 Søren Riisager
Søren Riisager
Page Content & AI
From August 2, 2026, undeclared AI-generated content will cost European companies up to 35 million euros in fines, which is why digital survival is now exclusively dictated by the full integration of cryptographic C2PA metadata and unbreakable editorial control mechanisms.
This is the new reality.
Many in the industry misunderstand the threat landscape. EU legislation does not regulate your organic visibility or Google’s algorithms; it regulates your company’s wallet directly. SEO specialists who use illegal shortcuts for the mass production of synthetic content will be punished with fines that can shut down the company. The requirements for digital publishing and SEO are undergoing a fundamental, legislative change of course that eliminates the unregulated and opaque use of generative artificial intelligence. Companies, marketing agencies, and independent publishers are subject to an absolute compulsion to restructure their digital infrastructures to meet a series of strict, cross-cutting compliance mechanisms. The EU AI Act’s rule set analytically and legally distinguishes sharply between the developers of the technology and the commercial entities that use it. The law introduces an uncompromising requirement for transparency that cuts across text, audio, image, and video.
Think about this:
The legislation does not only hit the multinational tech giants in Silicon Valley. It penetrates the engine room of every digital marketing team, every SEO specialist, and every content producer operating within the European market, regardless of company size. To avoid these draconian financial sanctions, a methodical, almost forensic integration of technical metadata, visible declarations, and logged human control mechanisms is required.
The legal foundation: Article 50 deconstructed
Article 50 of the EU AI Act constitutes the central legislative backbone for transparency in AI-generated content. The ontology of the rule set addresses the risk of systematic manipulation and misinformation by forcing market actors to permanently deconstruct the illusion of human origin that synthetic content inherently creates. To operationalize the legislation, a legal distinction is made between two primary actor types with radically different obligations: Providers and Deployers.
Providers are defined as the entities that develop, train, and distribute the generative AI systems and General-Purpose AI (GPAI) models. Their obligation is strictly technical. They must ensure at the architectural level that the system’s output is automatically equipped with machine-readable metadata that permanently identifies the content as artificially generated or algorithmically manipulated. This codification must be technologically effective, interoperable across platforms, and resistant to malicious removal attempts. It must be based on what the legislation calls “the generally acknowledged state of the art,” which in practice refers to open technical standards.
Deployers make up the other party. These are the organizations, PR agencies, SEO departments, and individual publishers that use the AI systems to produce and publish commercial or informative content. Their obligation is operational, contextual, and directly aimed at the end-user’s perception. As a deployer, it is an absolute requirement that deepfakes and certain types of synthetic text are declared unambiguously. The labeling must be done proactively, no later than the exact moment the user is first exposed to the content, and must be communicated in a clear, easily understandable, and universally accessible manner that takes into account persons with disabilities.
Here is why:
The EU Commission’s goal is to ensure the structural integrity of the entire European information ecosystem without stifling commercial innovation. To facilitate and standardize the transition, the EU’s AI Office has initiated the drafting of an official Code of Practice. This code is currently being drafted in collaboration with independent, selected experts. It establishes two specific working groups matching the legal divide between providers and deployers, aiming to create standardized, operational protocols for compliance before the law’s final entry into force in August 2026. Working Group 1 focuses on the interoperability of technical solutions, while Working Group 2 focuses on disclosure mechanisms for deepfakes and texts of public interest.
| Actor type in EU AI Act | Legal Definition | Primary Obligations (Article 50) | Exceptions for Transparency |
|---|---|---|---|
| Providers | Developers of generative AI systems and GPAI models. | Embedding machine-readable metadata (watermarking/hashing). Creation of detection tools via API. | System only performs standard assisting editing. System does not substantially change input data. |
| Deployers | Content producers, agencies, and publishers. | Clear and visible declaration of deepfakes and texts of public interest at first exposure. | Clearly artistic/satirical content. Logged and genuine human review. |
The technical architecture: C2PA and multi-layered labeling
Transparency has, under the AI regulation, ceased to be a superficial, theoretical exercise. The legislation prescribes a stringent, multi-layered labeling strategy, as the European legislative body has recognized that no single labeling technique is deemed sufficiently robust against manipulation and file conversion. For publishers, this results in an unavoidable architecture consisting of both visible user declarations and invisible, cryptographic layers.
The visible labeling functions solely as the first, human-facing line of defense. Acceptable formats include explicit sentences like “AI-generated content” or “Synthetic audio generated by AI”. Ambiguous phrasing, visual rewrites, or hidden declarations in footers constitute a direct breach of the legislation. The placement of the labels is subject to strict regulation: They must appear at the absolute beginning of a text, in immediate, inseparable proximity to image and video material, or be communicated aurally before the playback of an audio file is initiated. The Code of Practice details the use of a standardized icon-based system to ensure immediate recognizability across European platforms.
The truth is different:
It is the machine-readable metadata that forms the long-term foundation for compliance, algorithmic trust, and content authority. This is where the SEO infrastructure is won or lost. The EU AI Act requires trust metadata to be permanently embedded into the core of the file. C2PA (Coalition for Content Provenance and Authenticity) has quickly established itself as the global gold standard for exactly this digital discipline. The C2PA standard enables an indisputable ‘chain of custody’, where X.509 digital certificates and asymmetric cryptographic hashing log all information about the exact origin of the content and all sequential changes made since its creation.
This protocol systemically protects against manipulation. Unlike conventional EXIF data, which can easily be deleted or modified by third parties, the C2PA manifest is designed to survive re-uploads, format changes, and sharing across closed platforms. If the C2PA data is removed or corrupted, the cryptographic signature is broken, automatically marking the file as unverified for search engines and platforms.
The metadata injection must accommodate a specific constellation of mandatory fields. These fields include the unique identifier of the AI system or provider, a cryptographically validated confirmation of the use of synthetic generation, and an immutable timestamp of the file’s creation. Google specifically supports properties such as contentUrl, creator, creditText, copyrightNotice, and license in their machine reading of these manifests.
For operators, web developers, and SEO specialists who already work with embedding signatures, the time horizon is critical. The industry is implementing a phase-out of outdated standards. From January 2026, an absolute “freeze” on Legacy ITL certificates will be initiated. Content previously signed with these certificates will not be invalidated, but they will transition to being a legacy trust marker. Going forward, validation tools will exclusively accept signatures based on the updated C2PA Trust List. This increases the pressure on companies to immediately update their technical publishing workflows, CMS integrations, and digital asset management (DAM) systems before the legislation hits with full force.
The SEO paradigm shift: From keywords to cryptographic trust
The integration of cryptographic transparency operates in direct, reinforcing synergy with search engines’ own fundamental algorithmic updates. The EU AI Act accelerates a seismic shift in modern SEO strategies; a shift away from iterative keyword hunting towards intent-matching, entity-driven architecture, and source credibility. As the digital market is flooded with automated, low-quality synthetic content, search algorithms increasingly configure label transparency and verified C2PA validity as significant, decisive E-E-A-T signals (Experience, Expertise, Authoritativeness, Trustworthiness).
The consequence is clear:
Labeling AI content is not automatically punished with degradation in Google Search. On the contrary, transparency functions as an essential trust signal that correlates positively with the machine and human perception of reliability. Google is already in the process of a massive integration of C2PA metadata into core products like Google Search, Google Images, Google Lens, and the Ads ecosystem. This translates into features like “About this image” directly integrated into the SERP (Search Engine Results Page), giving end-users extreme and immediate context. Independent analysts estimate that search engines will, by the end of 2026 at the latest, incorporate uninterrupted C2PA validity as a direct, weighted ranking parameter. Domains that systematically publish images, videos, or articles without a signed, verifiable history are expected in the short term to experience declining organic indexing priority and reduced visibility in Discover feeds.
In the broader information ecosystem, a drastic drop in traditional organic traffic for simple informative queries is observed. The reason is the proliferation of AI Overviews, which extract and present synthesized answers directly in the search result, thereby eliminating the need for a click. Recent comprehensive analyses based on hundreds of thousands of search results indicate a near halving of AI citations from top-10 organic rankings over just one year. Rankings on page one are no longer a guarantee of being cited as a source by the large language models.
The search algorithms are shifting their focus instead. They heavily prioritize domains with broad topical coverage, heavy historical authority, and structured formats. Analyses unequivocally show that structured information - such as Government sites (.gov), platforms with support documentation, peer-reviewed studies, and domains like Wikipedia and YouTube - are massively rewarded in AI citations. Support documentation, for example, is over three times more likely to be extracted than baseline articles, solely due to the machines’ easy access to parse clearly structured FAQs and lists.
| SEO Strategy (Pre-2024) | SEO Strategy (EU AI Act & LLM Era, 2026+) | Algorithmic Signal |
|---|---|---|
| Keyword Density optimization | Intent-matching and conversational Q&A formats | Enhanced AI Comprehension |
| Most possible words on page | Direct, precise answers and task completion | Reduced friction for the user |
| Standard image EXIF data | C2PA cryptographic metadata and CAI Trust Lists | Technical and verifiable provenance |
| Isolated SEO landing pages | Deep, thematic coherence at domain level (Topic clusters) | Entity authority and E-E-A-T |
| Hiding automated text | Full transparency, bylines and “Genuine Human Review” | Prevention of regulatory penalties |
To survive this shift, the SEO architecture must be radically adapted to the reading patterns of AI systems and the requirements of the EU law. Tools like Tulabot, which allow free bulk checking of HTTP status and keyword research on real data, must be used to sanitize pages and build robust knowledge clusters. Content must be published in direct Q&A formats, stripped of superfluous wrapping and long introductions. Long-tail, conversational keywords are critical for accurate information extraction, as LLMs process data based on natural language use.
Companies operating in high-risk niches (Finance, Health, Law) will continue to be subject to a requirement for massive classic SEO efforts combined with aggressive, verifiable E-E-A-T proofs and transparent author entities. In contrast, players in broad, low-risk informative verticals will be forced to fundamentally change their strategy towards delivering machine-readable precision or pivot towards transactional intent to escape the LLMs’ information monopoly. The upcoming Google Core Update is further predicted to punish thin affiliate material in favor of “source-close” content; original data, firsthand experience, and transparent methodology will define the winners.
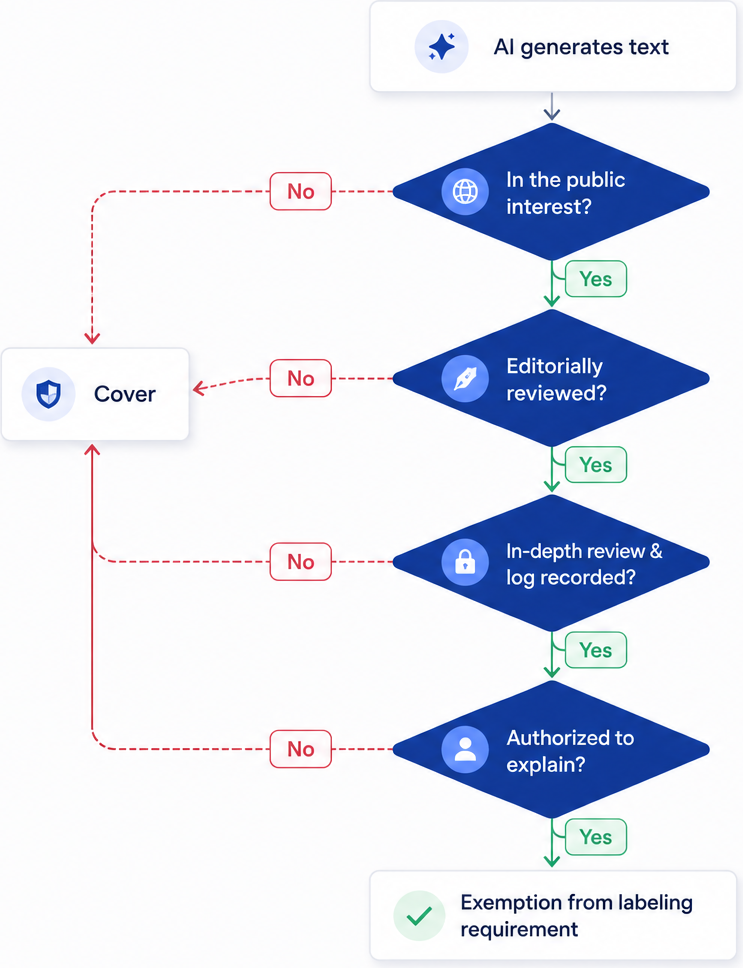
The exception mechanism: Dismantling the HITL illusion
There is a specific legal corridor in the AI Act that exceptionally exempts deployers from the strict obligation to declare and label AI-generated text. If a text is published with the explicit purpose of informing the public on matters of public interest (e.g., journalism or opinion-forming material), the declaration requirement can legally be circumvented. But only if the editorial process is subject to strict, documented human control.
The legislation defines this process under the terms “Genuine Human Review” and full editorial responsibility. To activate the exception, a natural or legal person must formally step forward, assume objective responsibility for the publication, and vouch for its accuracy.
This is not a loophole:
Many media houses and agencies live in the illusion that a lightly integrated “Human in the loop” (HITL) setup is sufficient. That is a fatal misinterpretation. An asymmetrical workflow where a single editor seconds-approves thousands of machine outputs before mass distribution is under no circumstances recognized as real editorial involvement in a legal sense. Genuine Human Review requires the integration of a structural, procedural fairness architecture right into the publishing engine. The human in the process must possess the unrestricted, formal authority to completely overturn the machine result. The procedure must include routes for objection, data correction, and most importantly: systematic logging of the reasons for both changes and approvals. The process fails legally the moment lack of time, pressure, or the agency’s incentive structures encourage blind acceptance of the system’s output without critical scrutiny.
The European Code of Practice closes the final theoretical loophole for evasion. To claim exemption from the labeling requirement for text, the code requires the implementation of traceable, internal procedures that can be presented immediately during regulatory audits. A simple verbal or informal claim of human intervention is invalid. The agency or company must maintain written compliance documentation that explicitly proves that editorial control has taken place and that responsibility is unambiguously assigned. This documentation scales with the size of the company, but even in SMEs and independent SEO agencies, it is expected that audit processes are maintained formally and anchored in internal procedures.
For the PR industry, content marketing agencies, and news platforms, this means an immediate transition from automated mass publishing to stringent, manual approval protocols. Measure 5 in the Code of Practice actively narrows the exception so that publishers are forced to document an identifiable workflow rather than merely claiming human presence. This constitutes a significant bottleneck for the scalability of AI text, but in return ensures protection against draconian sanctions.
Copyright and Article 53: Transparency in training data
The development of machine learning models and robust General-Purpose AI (GPAI) systems relies on the ingestion of astronomical amounts of unstructured training data. Progress in artificial intelligence has historically relied on scraping the web without the consent of rights holders, creating a severe global conflict between software developers and content creators. The EU AI Act addresses this conflict directly through Article 53, which introduces mandatory transparency requirements for any provider of GPAI models placing their product on the European market.
The law establishes an extraterritorial reach. The obligations apply regardless of whether the actual model training took place in the US, Asia, or internally in the EU; if the company wants market access in Europe, the rules must be followed. The era of unrestricted web scraping is subjected to rigid legislative control, where compliance with the EU’s DSM Directive (Directive on Copyright in the Digital Single Market) is centralized as a critical business protocol.
This is the foundation:
All providers of GPAI - covering the spectrum from closed commercial flagship models to certain types of open systems - are legally obliged to implement and execute a formal policy for compliance with European copyright legislation. The core of this compliance mandate is the preparation of a publicly available, “sufficiently detailed” summary of the content and the specific datasets used during model training.
To ensure structural uniformity, the EU’s AI Office, under the Commission, has prepared and published a mandatory template that defines the minimum requirements for this public transparency. The rollout marks a decisive shift from voluntary industry norms to legally binding obligations.
The template forces GPAI providers to document and publish information at a high, structured aggregated level. It does not require identification of every single protected work but operates with three main sections: First, ‘General Information’, requiring model identification, knowledge cut-off dates, data inventory based on modality (text, audio, video), and estimated data volumes calculated in tokens or gigabytes. Second, a ‘List of Data Sources’, where the provider must disclose the use of specific public databases, private registries, web-scraped data, synthetic content, and aggregated user data.
The architecture of this template constitutes a deliberate balancing act. It weighs the public’s and creators’ legitimate claims to content control against the technology providers’ commercial necessity to protect business-critical trade secrets. The template therefore does not require exposing the underlying algorithmic structures, neural architectures, or granular data processing operations. The purpose is pragmatic: to equip journalists, media actors, authors, and rights holders with a quantitative overview detailed enough so they can effectively monitor the use of their works, claim their rights, and issue formal opt-outs against machine text and data mining (TDM).
The regulation further differentiates based on system risk and licensing models. Open source models are favored with a reduced administrative burden. They are primarily exempt from delivering extended technical documentation to downstream providers and national authorities. However, it is a conditional exemption: Even free, open models are obliged to present training data summaries and respect copyright provisions.
The conditions are severely tightened upon two specific triggers. First: If the open source model is monetized - for example via commercial dual licenses, paid support, or if it collects personal data for commercial gain - the exceptions completely lapse. Second: If the model operates with unusually high capacity and is classified as having “systemic risk” (a threshold defined as training exceeding 10^25 FLOPs), it is subject to maximum regulation regardless of license form. Such models trigger strict requirements for notification to the Commission within 14 days, mandatory reporting of serious incidents, and proactive adversarial testing.
Downstream deployers, including software companies building on top of existing GPAI, must exercise extreme caution. If the modifications to the foundation model are substantial, and the computing power exceeds a third of the original model’s compute, the deployer legally transitions to being the new “provider” with the accompanying full obligations for the added data basis.
The financial risk picture: Asymmetrical sanctions
Inability or unwillingness to integrate the EU AI Act’s directives is not punished with friendly recommendations, dialogue, or mild injunctions. European legislators have structured the sanctions specifically for one purpose: To crush any form of economic profitability by operating outside the compliance frameworks. The fine system operates asymmetrically based on the nature of the violation and is measured directly as a percentage of the company’s global turnover. This is legislation with teeth, designed to hit boardrooms hard.
The system operates with three distinct tiers for violations.
Tier 1 represents the absolute heaviest sanction framework and is activated upon violation of prohibited AI practices (for example social scoring systems or manipulation technology). The penalty for use or distribution of these systems triggers administrative fines of up to 35 million EUR or a full 7% of the company’s total annual global turnover from the preceding financial year - and authorities will consistently collect whichever amount is higher. This penalty framework exceeds the dimensions of GDPR and unambiguously establishes the EU AI Act as the most costly technological regulatory regime in European history.
Think about this:
The biggest threat to the marketing, SEO, and content industry does not lie in the prohibited systems, but in Tier 2. Errors in compliance around transparency and documentation are costly. Breach of obligations under Article 50 (lack of declaration of deepfakes, lack of watermarking of AI text) as well as inadequate compliance with data governance, technical documentation, or cybersecurity for high-risk systems result in astronomical fines. Here, the hammer falls at up to 15 million EUR or 3% of the annual global turnover. This hits directly and unprotected those “deployers” who publish public texts without the required Genuine Human Review, or the companies that illegally let HR algorithms screen job candidates without informing them.
Tier 3 acts as a catch-net for bureaucratic and procedural violations. Provision of incorrect, incomplete, or directly misleading information to national supervisory authorities or the AI Office is punished severely, with fines that can reach up to 7.5 million EUR or 1% of the global turnover. This fine can easily be triggered by attempts to cover up missing C2PA implementations or false claims of human control processes.
The principle of proportionality integrated in the law’s Article 99 provides a marginal form of economic asylum for smaller players. When assessing fines against small and medium-sized enterprises (SMEs) and startups, the sanction will at most hit the lower of the two thresholds (absolute amount vs. percentage of turnover) to ensure their economic survivability. This does not exempt them from compliance, it simply reduces the risk of bankruptcy in the event of an unintentional error.
Additionally, the EU Commission is equipped with direct enforcement powers against the heaviest players. Under Article 101, the Commission can exclusively sanction providers of GPAI models and issue fines of up to 3% of global turnover or 15 million EUR if the provider negligently or intentionally violates the documentation requirements or copyright rules in Article 53.

Operational implementation in a Danish and European reality
The time horizon allows for no systemic delays. Although full legal application for transparency for generative systems takes effect in August 2026, the AI regulation is implemented in overlapping phases. Rules regarding prohibited AI practices and the basic requirements for AI Literacy took effect already in February 2025, while governance rules for GPAI are implemented over the summer of 2025. The rules for high-risk systems integrated into physical products are postponed to 2028 as a result of the “AI omnibus” agreement. For operators, marketing agencies, and enterprise organizations, this staggered reality demands an immediate, systematic, and cross-cutting reorganization of workflows.
In a Danish context, advising and enforcement are orchestrated through a complex collaboration between the Danish Agency for Digital Government (Digst), Danish Standards, the Danish Chamber of Commerce, and the Confederation of Danish Industry (DI). The Danish Agency for Digital Government, specifically the Office for AI, analysis and inclusion, sets the state guidelines, facilitates the national supervision, and publishes cases on companies’ usage.
The Confederation of Danish Industry and the Danish Chamber of Commerce repeatedly emphasize that marketing constitutes one of the most vulnerable domains. The requirement for AI Literacy does not constitute a soft recommendation, but is cemented as a hard legal requirement subject to the DS/PAS 2500-4:2025 standard. This means that management bears the legal responsibility to establish transparency internally in the organization and build practical AI skills so employees understand how and why a system arrives at specific results. Ignorance of the system’s data foundation or inherent bias is disqualified as a legal defense.
The legal interfaces between the client and the contractor (the SEO or content agency) must necessarily be rewritten. The responsibility for transparency under Article 50 pushes the burden of responsibility for undeclared deepfakes directly onto the agencies, unless contracts explicitly stipulate data governance and defined approval loops. A complete clarification of supplier responsibility and editorial responsibility becomes the focal point in any future service agreement.
The final compliance infrastructure
To survive the transition to the fully regulated era - and to avoid compromising basic business operations - any professional content producer must effectuate the protocol below before August 2026. If the process fails in just one of these links, the consequence is not a harmless ranking drop in Google, but instead direct legal and financial sanctions for breaching the transparency laws.
| Domain | Necessary Action for Full Compliance |
|---|---|
| Technical Labeling (Provider/Tool) | Implement C2PA-compatible publishing systems before January 2026 to avoid getting caught in the ITL certificate freeze. Protect metadata against compression stripping. |
| Visual Declaration (Deployer) | Incorporate recognized, visible user warnings (text/icons) directly at first exposure to synthetic audio, image, or video. Do not hide them in the footer. |
| Editorial Workflow (Article 50.4) | Draft and implement an internal compliance manual. Establish logged “Genuine Human Review” with a designated responsible editor to escape text-labeling requirements for informative content. |
| Data Audit & AI Literacy (DS/PAS) | Conduct a total audit of all AI plugins in the organization. Complete mandatory training for employees in practical AI skills and copyright understanding. |
| SEO Transition (LLM Optimization) | Adapt content to a conversational Q&A structure. Build deep topical clusters and support E-E-A-T via transparent bylines, source citations, and schema markup. |
| Contractual Safeguarding (Legal) | Update freelancer and agency contracts with specific clauses regarding supplier responsibility, transparency in prompts, and prohibition against unvalidated synthetic production. |